Click here for Learning Curve in PDF format.
According to a 2002 report released by the U.S. Department of Commerce's National Institute of Standards and Technology (NIST), software errors (or bugs) cost the U.S. economy USD59.5 billion annually. The study found that although all errors could not be removed, more than a third of these costs could be eliminated by an improved testing infrastructure that enables earlier and more effective identifcation and removal of software defects.
The financial derivatives industry is of course not immune to software errors, especially as far as the implementation of mathematical models is concerned. Consider, for example, the valuation of a simple European call option with strike X using the familiar Black-Scholes formula, namely
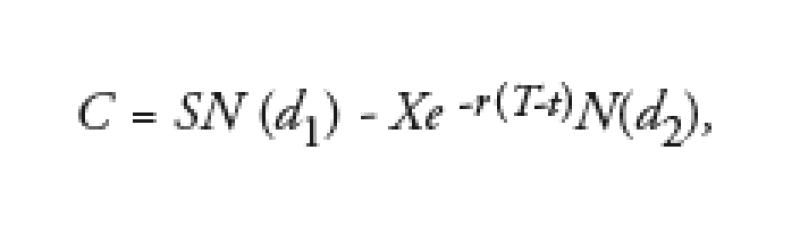
where
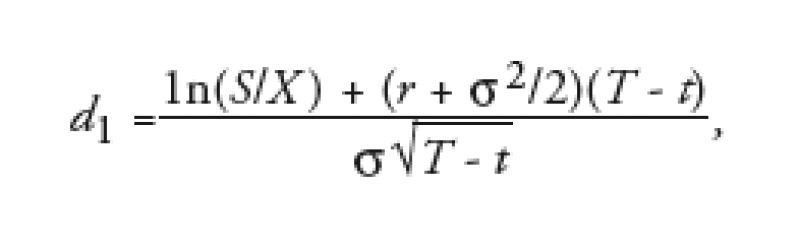
and
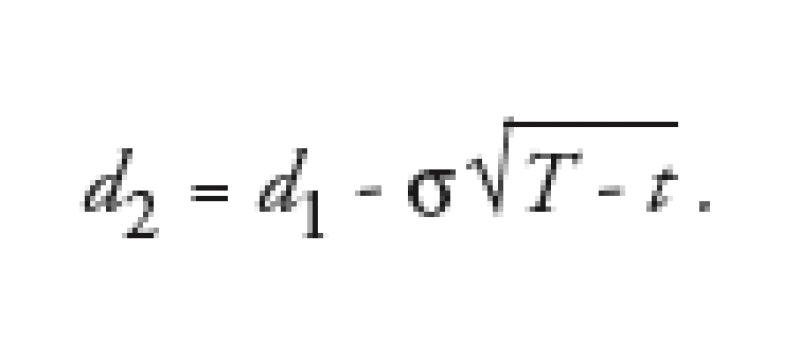
We use * to denote the so-called volatility of the underlying and r denotes the appropriate risk-free rate. The expiry date of the option is denoted by T and the present date by t. Furthermore
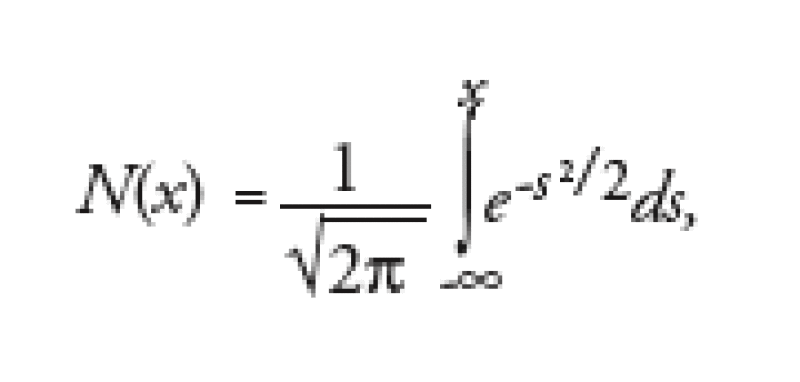
is the cumulative normal distribution function.
Since no closed-form solution exists for the cumulative normal distribution function we have to use numerical methods to evaluate it. One such approximation is given by
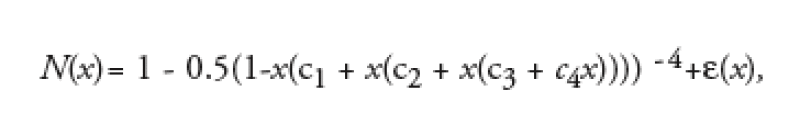
where x >= 0 and
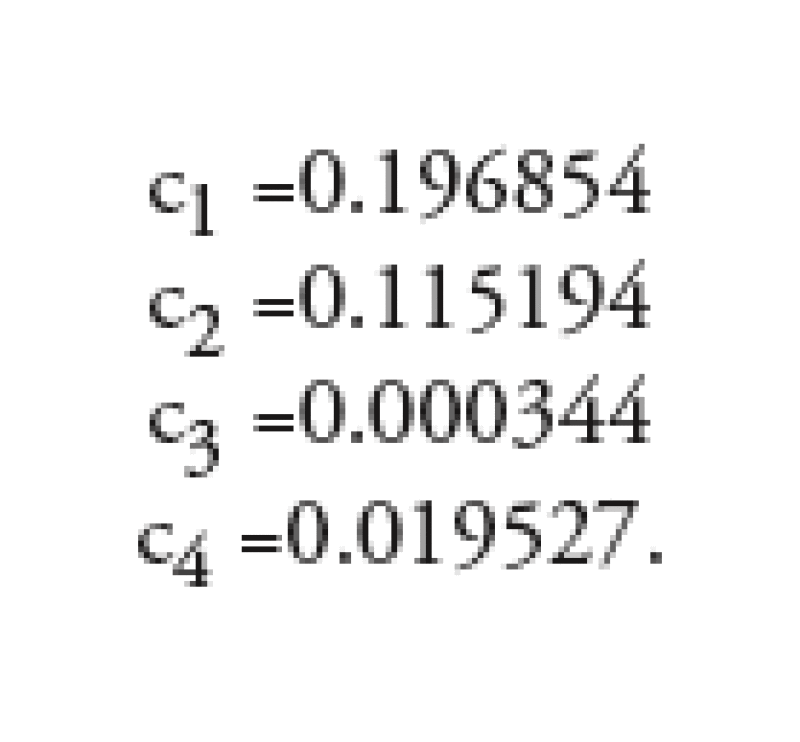
The error in this approximation is
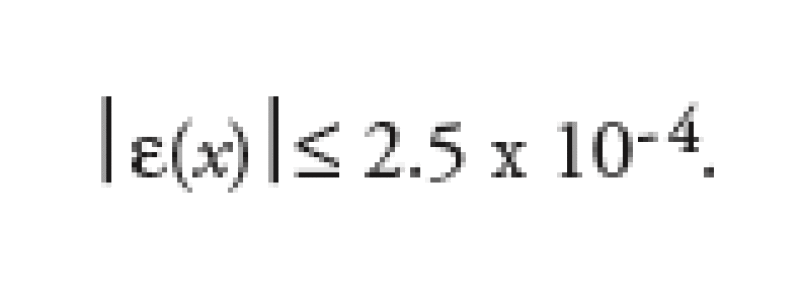
For numerical evaluation purposes we consider the price of a six-month European call option on a stock trading at S = 100 with a strike of X = 125. We shall use the risk free rate as r = 10%, while the volatility is chosen as * = 25%.
To our surprise, and frustration, the implementation yields answers that are not arbitrage free.
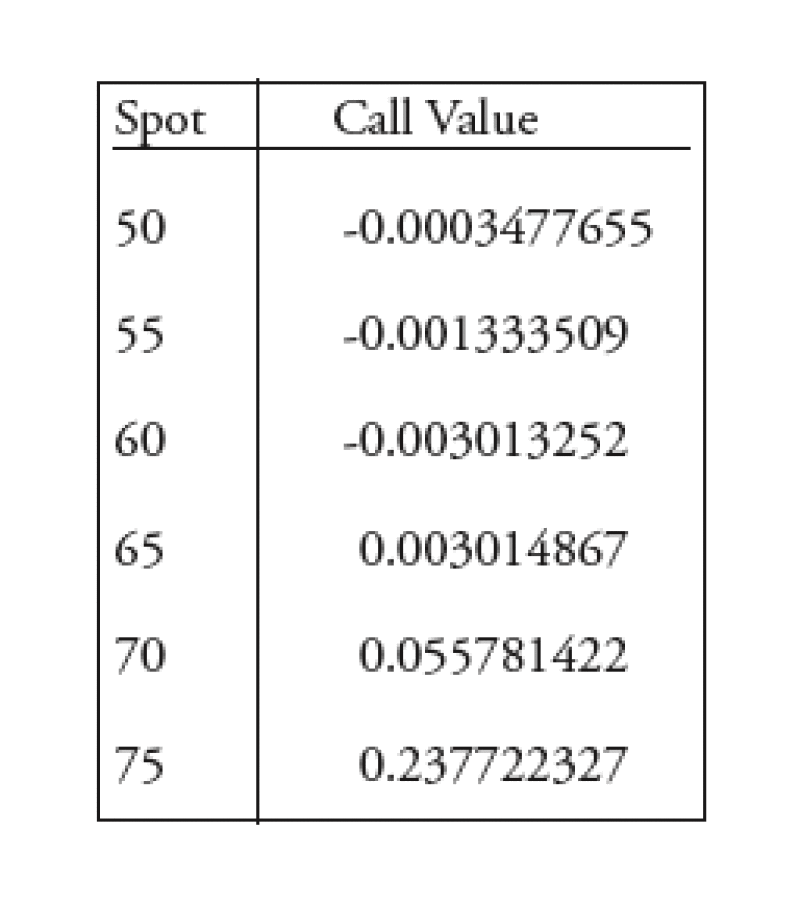
As shown in the table the option becomes negative for certain spot values. This is of course a direct consequence of approximating the cumulative normal distribution by using the expression above; which seemed appropriate but only revealed to be inadequate through testing.
It should be clear from this example that the sophisticated mathematics we derive from complex models sometimes turns into garbage as a result of software implementation.
Testing Framework: Methodology And Process
Let us consider some questions that should be asked when testing derivative software. Three different possibilities exist. Firstly, consider the problem of testing an implementation of a model for which a closed-form solution exists. Secondly, consider testing of a numerically implemented model within a known paradigm. The third problem pertains to the testing of a 'Black Box' which we shall not discuss here.
In all cases a testing approach should ideally include an independent model build by the person performing the testing. One should decide on an error tolerance before commencing testing. The tolerance should be chosen so as to reflect the dimensionality and path dependency of the problem bearing the analytic tractability of the problem in mind. On the one hand, one should expect error tolerances within machine accuracy for analytic solutions but on the other hand bigger errors for a Monte-Carlo simulation.
CASE A
Firstly, consider a model for which a closed-form analytical solution is known. We need to answer the following questions to satisfy ourselves of the implementation:
(1) How has the analytical solution been derived? Can we replicate the formulae?
(2) Do we understand the inputs to the models?
(3) Do we need to make approximations to evaluate analytical expressions?
If we do, how accurate are those approximations?
(4) Are we able to reproduce the same results as per the solution for a wide range of inputs?
(5) How do we test 'psychological' cases? Examples are:
* The value of an option at expiry.
* Behavior of a model for very small/large values of the underlying.
* Compliance with boundary conditions, for example, barrier options.
* Understanding of path dependant characteristics. As an example, what happens at the resets of an Asian option?
* Are there areas where the solution does not exist?
* How do we cater for discrete dividends?
(6) Of equal importance to accurate calculation of prices would be the calculation of the Greeks. These are frequently cumbersome to evaluate analytically, hence approximations are often used in their evaluation. One should ensure that the same process is followed to ensure the accuracy of the Greeks as with the model prices.
(7) In general, for closed-form solutions, we should be able to replicate results between the system and a test model within machine accuracy. If answers between the system and our test model differ we should investigate the difference thoroughly and be able to explain the differences analytically.
CASE B
Consider the validation of a model that has been implemented using a numerical method. Clearly, the principles highlighted for Case A still hold and need to be adhered to, however, we also need to consider the following questions:
(1) Within an existing paradigm, how has the problem been discretized numerically?
(2) Determine the behavior of the model with respect to discretization parameters. Does the implementation converge to a single number as the discretization parameter becomes arbitrarily small?
(3) Is the model stable with respect to small movements in the underlying?
(4) Does the numerical accuracy suffer from an increase/decrease in time?
(5) Describe the solution for a wide range of inputs. Does the solution appear jagged or is it smooth? Explain the Greeks and examine their behavior.
(6) Examine errors between the model and a test model. Are the relative errors stable or widely fluctuating?
(7) Are the differences between the models reconcilable?
Conclusion
Testing of the mathematical implementation of derivative pricing models is by no means a trivial process. We have shown a number of possible errors to consider and pointed at various factors to test for. There are undoubtedly many more we could have considered.
In an environment where software (and software development) is definitely not cheap, top management sometimes adopts the attitude that "It was expensive therefore it must be right ..." It should be emphasized that any organization using financial derivatives should establish testing principles for software used to implement derivatives models. This should typically form part of their derivatives model verification process.
This week's Learning Curve was written by Eben Maré, professor in the department of mathematics and applied mathematics at the University of Pretoria, South Africa.





